
Содержание
Шахта
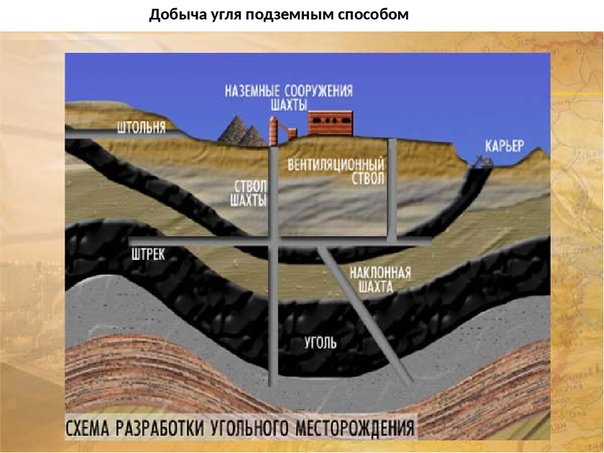
ШАХТА (а. mine, pit, соlliery; н. Grube, Zeche, Schachtanlage; ф. mine, siege, charbonnage, puits; и. mina, pozo, hullera) — производственный объект, осуществляющий добычу полезного ископаемого с помощью системы подземных горных выработок.
До середины 20 века под термином «Шахта» понималась вертикальная или наклонная горная выработка, пройденная с поверхности Земли по полезным ископаемым для разведки или вскрытия месторождений. В зависимости от назначения различали разновидности шахт: кунстшахта (оборудованная водоотливными машинами — т.н. водяная шахта), рихтшахта (разведочная), трейбшахта, фердершахта и циехшахта (оборудованные подъёмными машинами), форшахта (для входа и выхода горняков из шахты).
Прототипы шахты впервые появились в неолите в 8-7-м тысячелетии до н.э., когда с помощью горных орудий из рога, камня и дерева (кайла, мотыги, кирки и др.) при добыче кремня в земле стали прокладывать довольно сложные сети ходов-выработок (Граймс-Грейвс, Великобритания; Кварнбю, Швеция; Красное Село, CCCP, и др. ) вначале с естественно устойчивыми сводами, а затем сохраняемыми с помощью крепи или целиков. К 17-18 вв. сети горных выработок начинают складываться в чёткие пространственные системы со своими функциональными звеньями (вскрытия, подготовки, выемки), взаимосвязанные с технологическими процессами выемки, транспорта, проветривания и водоотлива, близкими к современной шахте. К концу 18 — началу 19 вв. глубины шахт в Европе в среднем достигают 400 (Фрайбергские рудники, Германия) — 600 м (рудники Гарца, Германия), максимально 1000 м (каменноугольные копи Камберленда, Великобритания), в России — около 200 м (Змеиногорский рудник).
) вначале с естественно устойчивыми сводами, а затем сохраняемыми с помощью крепи или целиков. К 17-18 вв. сети горных выработок начинают складываться в чёткие пространственные системы со своими функциональными звеньями (вскрытия, подготовки, выемки), взаимосвязанные с технологическими процессами выемки, транспорта, проветривания и водоотлива, близкими к современной шахте. К концу 18 — началу 19 вв. глубины шахт в Европе в среднем достигают 400 (Фрайбергские рудники, Германия) — 600 м (рудники Гарца, Германия), максимально 1000 м (каменноугольные копи Камберленда, Великобритания), в России — около 200 м (Змеиногорский рудник).
Реклама
Несмотря на интенсивное развитие с начала 20 века разработки залежей карьерами, шахты в конце 80-х гг. обеспечивают добычу около 80% каменных и 10% бурых углей, около 30% руд металлов и 15% нерудных полезных ископаемых. Масштабы добычи на отдельных шахтах достигают десятков млн. т в год (табл.).
Глубины угольных шахт уходят к отметкам 1,3-1,5 км, рудных — до 4 км (см.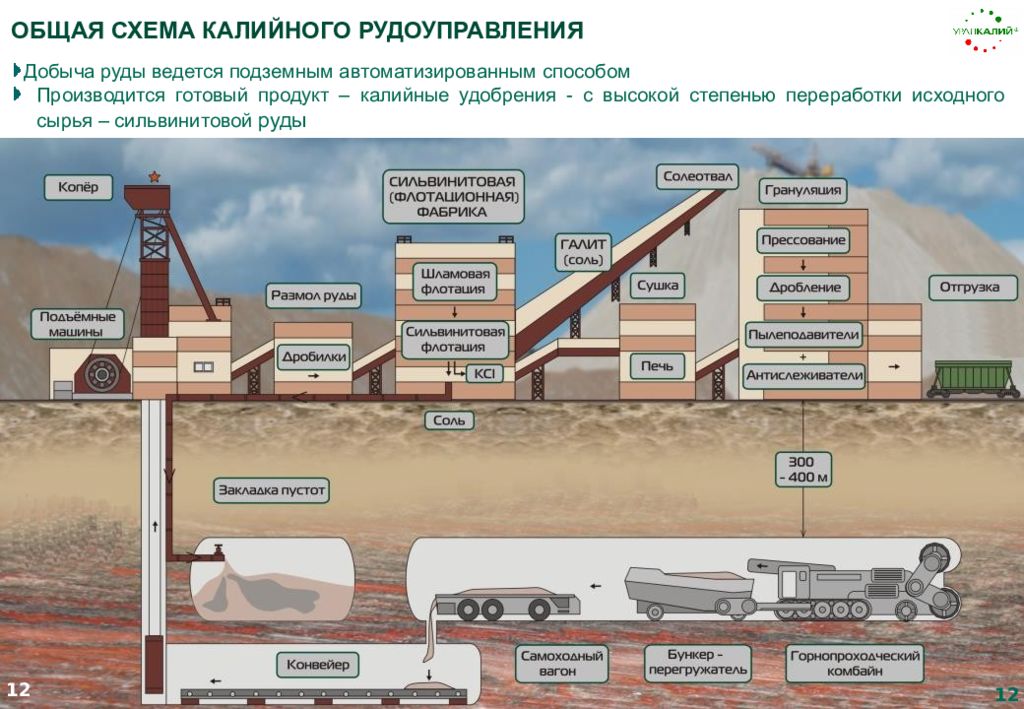 Глубокая шахта). Суммарные объёмы подземных выработок шахт достигают десятков тысяч м3, длина — десятков километров, в шахтах подаётся от нескольких сотен до нескольких тысяч м3 воздуха в минуту. На шахтах занято до нескольких тысяч человек.
Глубокая шахта). Суммарные объёмы подземных выработок шахт достигают десятков тысяч м3, длина — десятков километров, в шахтах подаётся от нескольких сотен до нескольких тысяч м3 воздуха в минуту. На шахтах занято до нескольких тысяч человек.
Каждая шахта (горное предприятие) имеет земельный и горный отводы, вскрытые и подготовленные к выемке кондиционные запасы, обеспечивающие нормальное развитие горных работ.
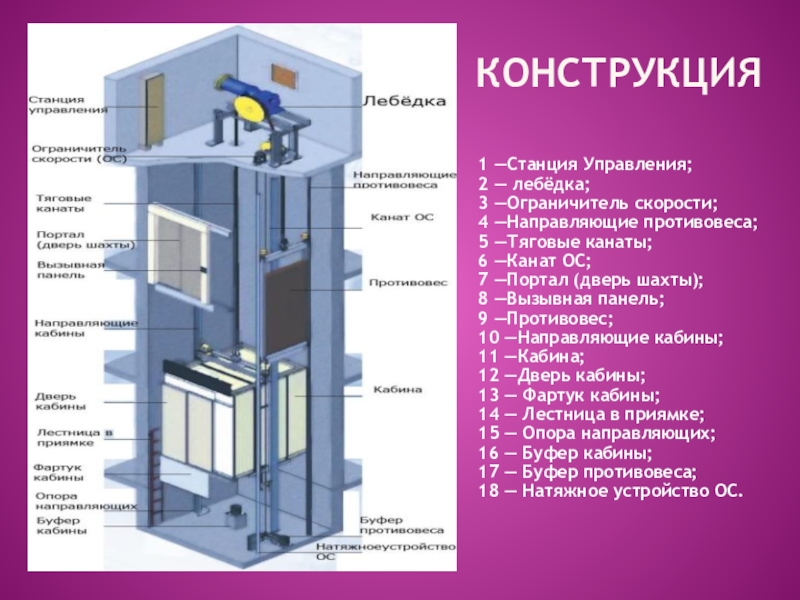
Современная шахта представляет собой взаимосвязанную производственную систему подземного хозяйства и технологического комплекса поверхности шахты (рис.).
Наряду с сетью подземных горных выработок и комплексом зданий (помещений), сооружений и устройств на поверхности, составными элементами шахт служат: устройства, оборудование, а также средства механизации и автоматизации производственных процессов; оборудование и устройства энергоснабжения; средства и устройства, обеспечивающие безопасную и комфортную работу; средства связи и управления; сооружения и средства, обеспечивающие охрану окружающей среды.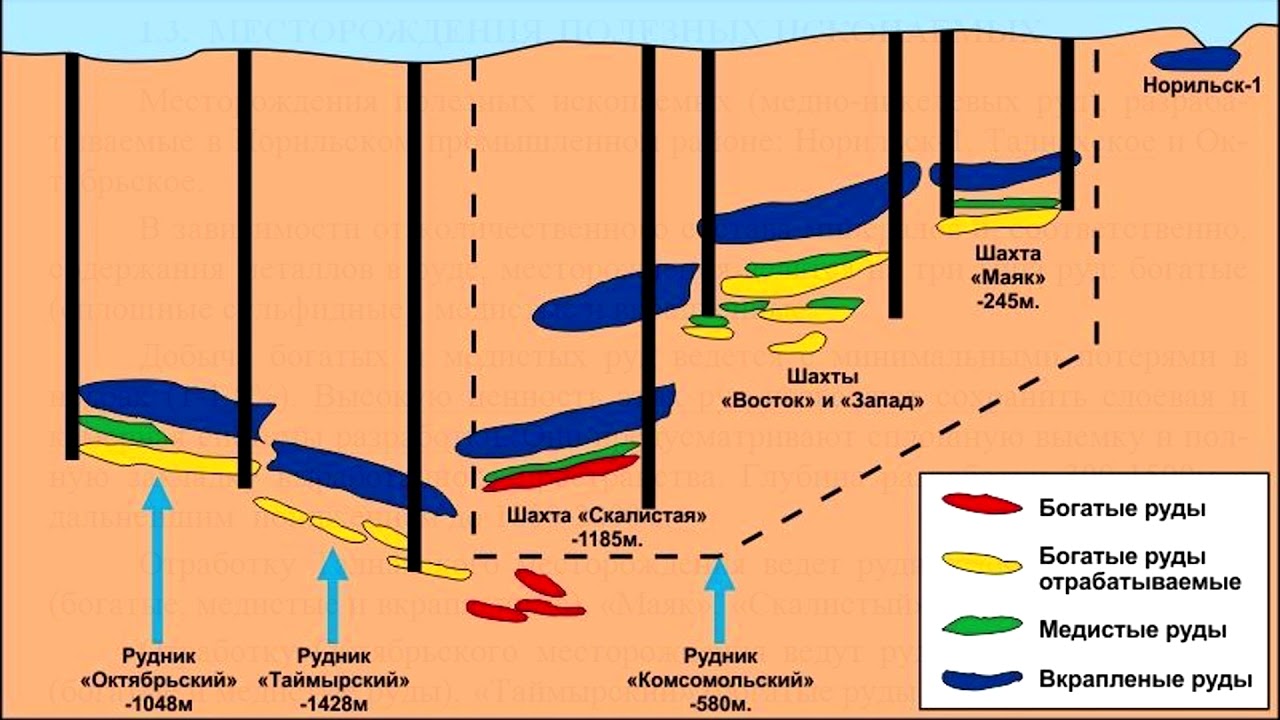
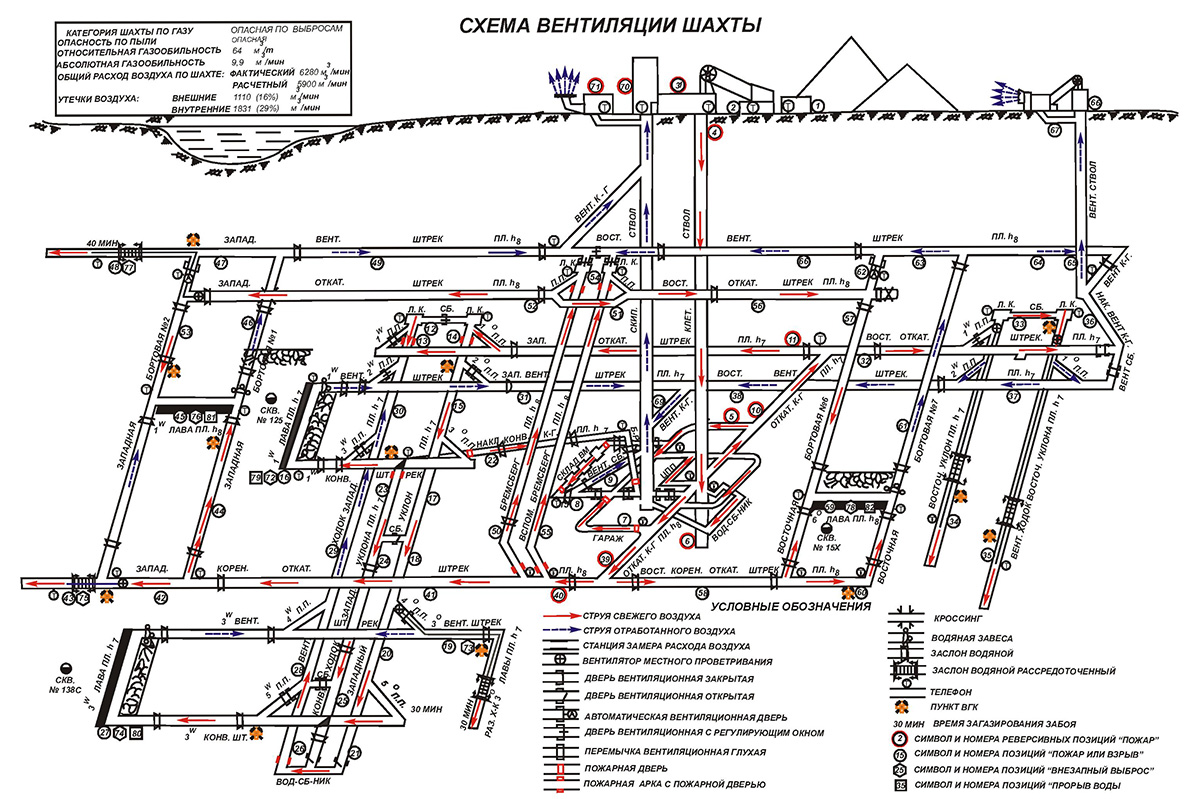
Характер ведения горных работ на шахте связан с видом и условиями залегания полезных ископаемых, которые предопределяют средства и способы добычи, организацию работ, режим работы горного предприятия. В единой структуре шахт можно выделить взаимосвязанные в пространстве и во времени зоны ведения очистных работ, работ по воспроизводству фронта очистной выемки (см. Горно-подготовительные работы), работ, связанных с шахтным транспортом, вентиляцией шахты, дегазацией, водоотливом, энергообеспечением (см. Электроснабжение горных предприятий) и др. Деятельность шахт в условиях разработки залежей, опасных по газу, внезапным выбросам и суфлярным выделениям, при выделении в шахтную атмосферу взрывоопасных или токсичных газов предопределяет особый режим работы подземного предприятия (см. Газовый режим).
Современная шахта — предприятие, добыча полезных ископаемых на которых, как правило, ведётся на принципах комплексной механизации и автоматизации. Подавляющее большинство лав угольных и сланцевых шахт оборудовано высокопроизводительными механизированными комплексами очистными. Очистные забои рудных шахт, выемка полезных ископаемых в которых осуществляется в процессе буровзрывных работ, оснащены самоходными буровыми, погрузочными, погрузочно-доставочными и другими машинами и оборудованием. Подготовительно-нарезные работы и горнопроходческие работы характеризуются широким развитием комбайновой технологии на угольных шахтах, а также применением на рудных шахтах различных видов самоходного безрельсового оборудования, самоходных полков и др. Все эти и другие основные и вспомогательные работы и производственные процессы, средства механизации и автоматизации, которыми они обеспечиваются, а также горные выработки, где они осуществляются, на современных шахтах взаимоувязаны в технологических схемах горнодобывающего предприятия. Наряду с шахтами, использующими традиционные технологии, на современном этапе организовано горнодобывающее производство на гидрошахтах, а также на шахтах, действующих на нефтяных месторождениях (см. Шахтная разработка нефтяных месторождений).
Очистные забои рудных шахт, выемка полезных ископаемых в которых осуществляется в процессе буровзрывных работ, оснащены самоходными буровыми, погрузочными, погрузочно-доставочными и другими машинами и оборудованием. Подготовительно-нарезные работы и горнопроходческие работы характеризуются широким развитием комбайновой технологии на угольных шахтах, а также применением на рудных шахтах различных видов самоходного безрельсового оборудования, самоходных полков и др. Все эти и другие основные и вспомогательные работы и производственные процессы, средства механизации и автоматизации, которыми они обеспечиваются, а также горные выработки, где они осуществляются, на современных шахтах взаимоувязаны в технологических схемах горнодобывающего предприятия. Наряду с шахтами, использующими традиционные технологии, на современном этапе организовано горнодобывающее производство на гидрошахтах, а также на шахтах, действующих на нефтяных месторождениях (см. Шахтная разработка нефтяных месторождений).
Срок существования шахт устанавливается технико-экономическим расчётом, который зависит от обеспеченности соответствующими запасами полезных ископаемых, вида добываемого сырья, производственной мощности предприятия и других факторов. Обычно этот срок составляет 15-40 лет. Минимальные сроки существования шахт 15-20 лет. Иногда золоторудные шахты, а при небольшой мощности также другие предприятия, эксплуатирующие богатые месторождения некоторых металлов, ценных видов неметаллического сырья, действуют 5-10 лет. Максимальные сроки 100 лет и более (в редких случаях), но обычно 40-50 лет у крупных угольных (сланцевых), а также рудных шахтах. При значительных запасах полезных ископаемых, определяющих длительную службу шахт, на предприятии производится реконструкция или техническое перевооружение. В случае изменения горно-геологических, гидрогеологических или технико-экономических условий разработки месторождения может производиться консервация шахт, а после полной отработки или списания балансовых запасов месторождения и при отсутствии перспектив их прироста — ликвидация шахт (порядок и условия их проведения регламентируются специальной инструкцией).
Обычно этот срок составляет 15-40 лет. Минимальные сроки существования шахт 15-20 лет. Иногда золоторудные шахты, а при небольшой мощности также другие предприятия, эксплуатирующие богатые месторождения некоторых металлов, ценных видов неметаллического сырья, действуют 5-10 лет. Максимальные сроки 100 лет и более (в редких случаях), но обычно 40-50 лет у крупных угольных (сланцевых), а также рудных шахтах. При значительных запасах полезных ископаемых, определяющих длительную службу шахт, на предприятии производится реконструкция или техническое перевооружение. В случае изменения горно-геологических, гидрогеологических или технико-экономических условий разработки месторождения может производиться консервация шахт, а после полной отработки или списания балансовых запасов месторождения и при отсутствии перспектив их прироста — ликвидация шахт (порядок и условия их проведения регламентируются специальной инструкцией).
Облик шахт, организация и характер проводимых в них работ в перспективе будут складываться в первую очередь под влиянием факторов, связанных с переходом на всё более глубокие горизонты, определяться всё возрастающими требованиями к охране окружающей среды. См. также Подземная разработка месторождений.
См. также Подземная разработка месторождений.
География
Шахты АО «Донуголь» расположены в Красносулинском районе Ростовской области. Через район проходит железная дорога СКЖД республиканского значения, связывающая юг России с центральной и северной частями. А также дорога, соединяющая восточную часть области с Украиной.
Недалеко от промышленных площадок шахт проходит автотрасса «Дон» «М4» «Москва—Ростов-на-Дону» федерального значения, соединяющая юг России с центральной частью и северными территориями.
Непосредственная близость к портам Черного и Азовского морей позволяет компании занять лидирующее место поставщиков антрацита на мировой рынок морской торговли
Расположение
Офис АО «Донуголь» расположен по адресу: 346316, Ростовская область, Красносулинский район, с.п. Михайловское, поселок Молодежный, улица Степная, здание 5, строение 1, этаж 1, помещение 1
«Обуховская № 1»
Промплощадка шахты находится в 15 км восточнее гор.
 Зверево. Ближайшая железнодорожная станция МПС «Божковская» находится в 3 км восточнее промплощадки.
Зверево. Ближайшая железнодорожная станция МПС «Божковская» находится в 3 км восточнее промплощадки.- «Шерловская-Наклонная»
Промплощадка шахты находится в 23 км восточнее гор. Зверево. Ближайший населенный пункт — хутор Грязновка, находится севернее, на расстоянии 2,5 км от шахты.
Ближайшая железнодорожная станция МПС «Божковская» находится в 5,5 км юго-западнее промплощадки, а в 2,8 км южнее нее проходит однопутный участок железной дороги общего пользования «Новомихайловская-Краснодонецкая».
 Зверево. Ближайшая железнодорожная станция МПС «Божковская» находится в 3 км восточнее промплощадки.
Зверево. Ближайшая железнодорожная станция МПС «Божковская» находится в 3 км восточнее промплощадки.Сеть автомобильных дорог
Шахты АО «Донуголь» расположены в районе с разветвленной сетью автомобильных дорог и связаны с населенными пунктами и другими промышленными объектами:
«Шерловская-Наклонная»
Участком федеральной трассы М-4 «Дон», расположенным в 14 км западнее шахты «Шерловская-Наклонная».
Подъездной дорогой от поселка «Молодежный», г. Зверево и от шахты «Дальняя», а также автодорогой местного значения между хутором Чернецов и поселком Тополевый.
- «Обуховская № 1»
Участком федеральной трассы М-4 «Дон», расположенным в 4 км юго-западнее шахты «Обуховская № 1».
Подъездной автодорогой к шахте «Дальняя» АО «Донской антрацит», примыкающей непосредственно к промплощадке шахты «Обуховская № 1».
Геология
- «Шерловская-Наклонная»
Шахта «Шерловская-Наклонная» в настоящее время отрабатывает пласт k2 в северо-восточной части шахтного поля шахты «Обуховская № 1». Пласт k2 геологической мощностью 1,14-1,35 метра, пологого залегания, простого строения, на всем участке шахтного поля относится к категории выдержаных. Пласт не склонен к самовозгоранию, не опасен по внезапным выбросам, не опасен по взрывчатости угольной пыли. С глубины 800 метров отнесен к угрожаемым по горным ударам. Шахта отнесена к категории негазовых. Средний водоприток в шахту составляет 185 м3/час.
- «Обуховская № 1»
В пределах лицензионного участка шахты «Обуховская № 1» залегает угольный пласт k2, уголь марки «А» (антрацит).
Шахтное поле находится в благоприятных структурно-тектонических условиях. Оно является наиболее перспективным по условиям отработки и по качественным характеристикам продуктивного пласта в данном угольном районе.Северная часть шахтного поля граничит с полем шахт «Дальняя» АО «Донской антрацит», северо-восточная – с полем шахты «Шерловская-Наклонная» АО «Донуголь», юго-западная — с шахтным полем шахты АО «ШУ «Обуховская». Размеры шахтного поля достигают до 11,1 километров по простиранию и до 5,5 километров по падению пласта. Площадь шахтного поля составляет 61 км2. Имеющихся запасов достаточно для работы шахты «Обуховская № 1» с проектной мощностью 3,0 миллиона тонн ежегодно на протяжении более 40 лет.
 Шахтное поле находится в благоприятных структурно-тектонических условиях. Оно является наиболее перспективным по условиям отработки и по качественным характеристикам продуктивного пласта в данном угольном районе.
Шахтное поле находится в благоприятных структурно-тектонических условиях. Оно является наиболее перспективным по условиям отработки и по качественным характеристикам продуктивного пласта в данном угольном районе.Геология
«Шерловская-Наклонная»
| 1 миллион тонн/год | Проектная мощность по горной массе |
| 760 тысяч тонн/год | Проектная мощность по товарной продукции |
| 12,05 миллионов тонн | Балансовые запасы угля |
| 10,5 миллионов тонн | Промышленные запасы угля |
«Обуховская № 1»
| 111,55 миллиона тонн | Балансовые запасы угля |
| 85,9 миллионов тонн | Промышленные запасы угля |
Обратная связь
Оставьте заявку, чтобы начать работать вместе
Структуры интеллектуального анализа данных (службы анализа — интеллектуальный анализ данных)
- Статья
Применимо к:
SQL Server 2019 и более ранние версии служб Analysis Services
Службы анализа Azure
Power BI Premium
Important
Интеллектуальный анализ данных устарел в службах SQL Server 2017 Analysis Services и больше не поддерживается в службах SQL Server 2022 Analysis Services. Документация не обновляется для устаревших и прекращенных функций. Дополнительные сведения см. в статье обратная совместимость служб Analysis Services.
Структура интеллектуального анализа данных определяет данные, из которых строятся модели интеллектуального анализа данных: она определяет представление исходных данных, количество и тип столбцов, а также необязательное разделение на наборы для обучения и тестирования. Одна структура интеллектуального анализа данных может поддерживать несколько моделей интеллектуального анализа данных, которые используют один и тот же домен. Следующая диаграмма иллюстрирует связь структуры интеллектуального анализа данных с источником данных и с входящими в его состав моделями интеллектуального анализа данных.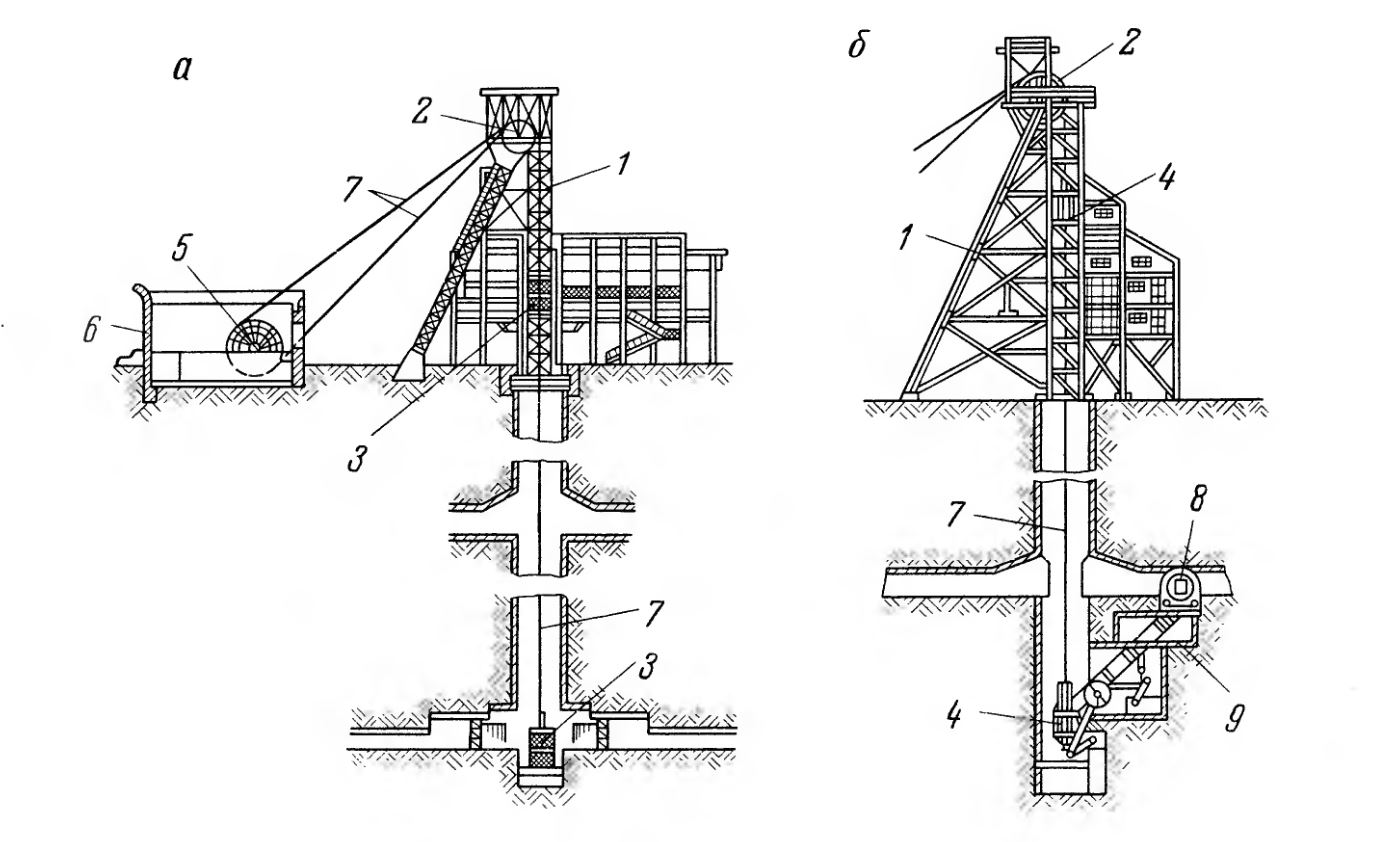
Структура интеллектуального анализа данных на диаграмме основана на источнике данных, который содержит несколько таблиц или представлений, объединенных полем CustomerID. Одна таблица содержит информацию о клиентах, такую как географический регион, возраст, доход и пол, а связанная вложенная таблица содержит несколько строк дополнительной информации о каждом покупателе, например о продуктах, которые он приобрел. На диаграмме показано, что несколько моделей могут быть построены на одной структуре интеллектуального анализа данных и что модели могут использовать разные столбцы из структуры.
Модель 1 Использует идентификатор клиента, доход, возраст, регион и фильтрует данные по региону.
Модель 2 Использует идентификатор клиента, доход, возраст, регион и фильтрует данные по возрасту.
Модель 3 Использует идентификатор клиента, возраст, пол и вложенную таблицу без фильтра.
Поскольку модели используют разные столбцы для ввода, а две модели дополнительно ограничивают данные, используемые в модели, путем применения фильтра, модели могут давать очень разные результаты, даже если они основаны на одних и тех же данных.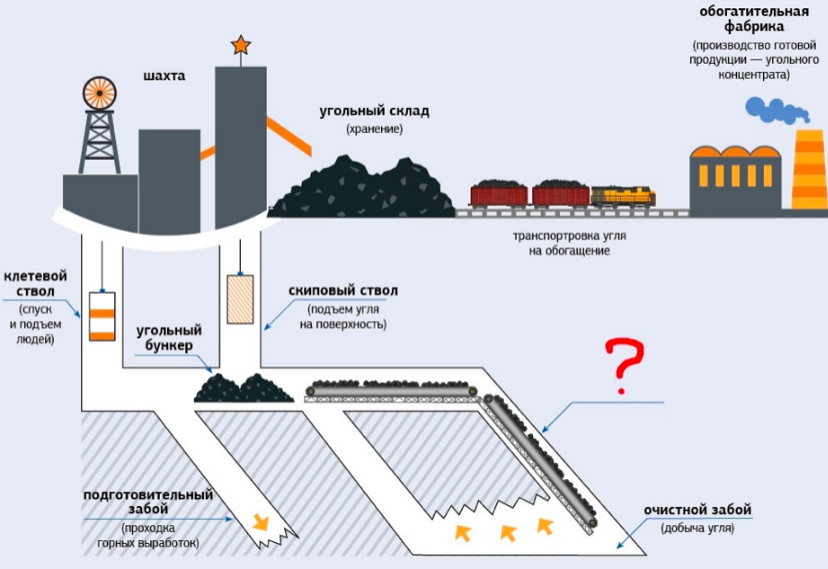 Обратите внимание, что столбец CustomerID является обязательным во всех моделях, поскольку это единственный доступный столбец, который можно использовать в качестве ключа обращения.
Обратите внимание, что столбец CustomerID является обязательным во всех моделях, поскольку это единственный доступный столбец, который можно использовать в качестве ключа обращения.
В этом разделе объясняется базовая архитектура структур интеллектуального анализа данных: как вы определяете структуру интеллектуального анализа данных, как вы заполняете ее данными и как вы используете ее для создания моделей. Дополнительные сведения о том, как управлять существующими структурами интеллектуального анализа данных или экспортировать их, см. в разделе Управление решениями и объектами интеллектуального анализа данных.
Определение структуры интеллектуального анализа данных
Настройка структуры интеллектуального анализа данных включает следующие шаги:
Определение источника данных.
Выберите столбцы данных для включения в структуру (не все столбцы нужно добавлять в модель) и определите ключ.
Определите ключ для структуры, включая ключ для лучшей таблицы, если применимо.
Укажите, должны ли исходные данные быть разделены на набор для обучения и набор для тестирования. Этот шаг является необязательным.
Обработать конструкцию.

Эти шаги более подробно описаны в следующих разделах.
Источники данных для структур интеллектуального анализа данных
При определении структуры интеллектуального анализа данных вы используете столбцы, доступные в представлении существующего источника данных. Представление источника данных — это общий объект, который позволяет объединять несколько источников данных и использовать их как единый источник. Исходные источники данных невидимы для клиентских приложений, и вы можете использовать свойства представления источника данных для изменения типов данных, создания агрегатов или псевдонимов столбцов.
Если вы строите несколько моделей интеллектуального анализа данных из одной и той же структуры интеллектуального анализа данных, модели могут использовать разные столбцы из этой структуры. Например, вы можете создать единую структуру, а затем построить из нее отдельное дерево решений и модели кластеризации, причем каждая модель использует разные столбцы и прогнозирует разные атрибуты.
Например, вы можете создать единую структуру, а затем построить из нее отдельное дерево решений и модели кластеризации, причем каждая модель использует разные столбцы и прогнозирует разные атрибуты.
Более того, каждая модель может использовать колонны из конструкции по-разному. Например, ваше представление источника данных может содержать столбец «Доход», который можно группировать по-разному для разных моделей.
Структура интеллектуального анализа данных хранит определение источника данных и столбцов в нем в виде привязок к исходным данным. Дополнительные сведения о привязках источников данных см. в разделе Источники данных и привязки (многомерные службы SSAS). Однако обратите внимание, что вы также можете создать структуру интеллектуального анализа данных без привязки ее к определенному источнику данных с помощью оператора DMX CREATE MINING STRUCTURE (DMX).
Столбцы структуры интеллектуального анализа данных
Стандартными блоками структуры интеллектуального анализа данных являются столбцы структуры интеллектуального анализа данных, которые описывают данные, содержащиеся в источнике данных. Эти столбцы содержат такую информацию, как тип данных, тип содержимого и способ распределения данных. Структура интеллектуального анализа данных не содержит сведений о том, как столбцы используются для конкретной модели интеллектуального анализа данных или о типе алгоритма, используемого для построения модели; эта информация определяется в самой модели интеллектуального анализа данных.
Эти столбцы содержат такую информацию, как тип данных, тип содержимого и способ распределения данных. Структура интеллектуального анализа данных не содержит сведений о том, как столбцы используются для конкретной модели интеллектуального анализа данных или о типе алгоритма, используемого для построения модели; эта информация определяется в самой модели интеллектуального анализа данных.
Структура интеллектуального анализа также может содержать вложенные таблицы. Вложенная таблица представляет отношение «один ко многим» между сущностью дела и связанными с ним атрибутами. Например, если информация, описывающая клиента, находится в одной таблице, а покупки клиента — в другой таблице, вы можете использовать вложенные таблицы для объединения информации в одно дело. Идентификатор клиента — это сущность, а покупки — связанные атрибуты. Дополнительные сведения о том, когда следует использовать вложенные таблицы, см. в разделе Вложенные таблицы (службы Analysis Services — интеллектуальный анализ данных).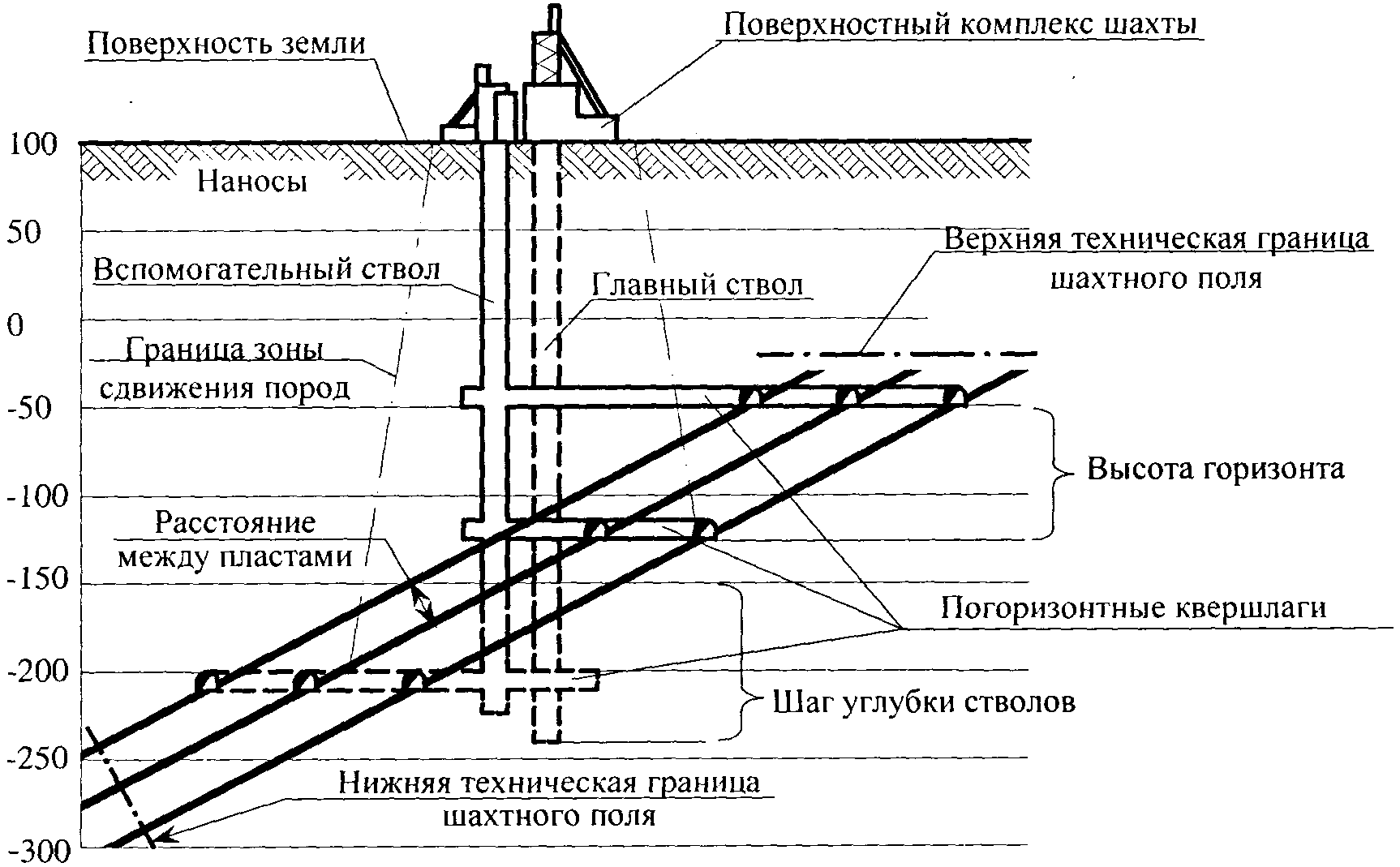
Чтобы создать модель интеллектуального анализа данных в SQL Server Data Tools, необходимо сначала создать структуру интеллектуального анализа данных. Мастер интеллектуального анализа данных проведет вас через процесс создания структуры интеллектуального анализа данных, выбора данных и добавления модели интеллектуального анализа данных.
Если вы создаете модель интеллектуального анализа данных с помощью расширений интеллектуального анализа данных (DMX), вы можете указать модель и столбцы в ней, и DMX автоматически создаст требуемую структуру интеллектуального анализа данных. Дополнительные сведения см. в разделе CREATE MINING MODEL (DMX).
Дополнительные сведения см. в разделе Столбцы структуры интеллектуального анализа данных.
Разделение данных на наборы для обучения и тестирования
При определении данных для структуры интеллектуального анализа данных можно также указать, что некоторые данные будут использоваться для обучения, а некоторые — для тестирования. Поэтому больше нет необходимости разделять данные перед созданием структуры интеллектуального анализа данных. Вместо этого при создании модели вы можете указать, что определенный процент данных должен быть сохранен для тестирования, а остальные использованы для обучения, или вы можете указать определенное количество случаев для использования в качестве набора тестовых данных. Информация о наборах данных для обучения и тестирования кэшируется со структурой интеллектуального анализа данных, и в результате один и тот же набор тестов может использоваться со всеми моделями, основанными на этой структуре.
Поэтому больше нет необходимости разделять данные перед созданием структуры интеллектуального анализа данных. Вместо этого при создании модели вы можете указать, что определенный процент данных должен быть сохранен для тестирования, а остальные использованы для обучения, или вы можете указать определенное количество случаев для использования в качестве набора тестовых данных. Информация о наборах данных для обучения и тестирования кэшируется со структурой интеллектуального анализа данных, и в результате один и тот же набор тестов может использоваться со всеми моделями, основанными на этой структуре.
Дополнительные сведения см. в разделе Наборы данных для обучения и тестирования.
Включение детализации
Вы можете добавлять столбцы в структуру интеллектуального анализа данных, даже если вы не планируете использовать столбец в конкретной модели интеллектуального анализа данных. Это полезно, если, например, вы хотите получить адреса электронной почты клиентов в модели кластеризации, не используя адрес электронной почты в процессе анализа. Чтобы игнорировать столбец на этапе анализа и прогнозирования, вы добавляете его в структуру, но не указываете использование для столбца или устанавливаете для флага использования значение «Игнорировать». Данные, помеченные таким образом, по-прежнему можно использовать в запросах, если в модели интеллектуального анализа данных включена детализация и у вас есть соответствующие разрешения. Например, вы можете просмотреть кластеры, полученные в результате анализа всех клиентов, а затем использовать запрос детализации для получения имен и адресов электронной почты клиентов в конкретном кластере, даже если эти столбцы данных не использовались для построения модели. .
Чтобы игнорировать столбец на этапе анализа и прогнозирования, вы добавляете его в структуру, но не указываете использование для столбца или устанавливаете для флага использования значение «Игнорировать». Данные, помеченные таким образом, по-прежнему можно использовать в запросах, если в модели интеллектуального анализа данных включена детализация и у вас есть соответствующие разрешения. Например, вы можете просмотреть кластеры, полученные в результате анализа всех клиентов, а затем использовать запрос детализации для получения имен и адресов электронной почты клиентов в конкретном кластере, даже если эти столбцы данных не использовались для построения модели. .
Дополнительные сведения см. в разделе Запросы детализации (интеллектуальный анализ данных).
Обработка структур интеллектуального анализа данных
Структура интеллектуального анализа данных является просто контейнером метаданных до тех пор, пока она не будет обработана. При обработке структуры интеллектуального анализа данных SQL Server Analysis Services создает кэш, в котором хранится статистика о данных, информация о дискретизации любых непрерывных атрибутов и другая информация, которая позже используется моделями интеллектуального анализа данных. Сама модель интеллектуального анализа данных не хранит эту сводную информацию, а вместо этого ссылается на информацию, которая была кэширована при обработке структуры интеллектуального анализа данных. Поэтому вам не нужно повторно обрабатывать структуру каждый раз, когда вы добавляете новую модель к существующей структуре; вы можете обработать только модель.
Сама модель интеллектуального анализа данных не хранит эту сводную информацию, а вместо этого ссылается на информацию, которая была кэширована при обработке структуры интеллектуального анализа данных. Поэтому вам не нужно повторно обрабатывать структуру каждый раз, когда вы добавляете новую модель к существующей структуре; вы можете обработать только модель.
Вы можете удалить этот кеш после обработки, если кеш очень большой или вы хотите удалить подробные данные. Если вы не хотите, чтобы данные кэшировались, вы можете изменить свойство CacheMode структуры интеллектуального анализа данных на ClearAfterProcessing . Это уничтожит кеш после обработки любых моделей. Установка для свойства CacheMode значения ClearAfterProcessing отключит детализацию из модели интеллектуального анализа данных.
Однако после того, как вы уничтожите тайник, вы не сможете добавлять новые модели в структуру майнинга. Если вы добавите в структуру новую модель интеллектуального анализа данных или измените свойства существующих моделей, вам потребуется сначала повторно обработать структуру интеллектуального анализа данных. Дополнительные сведения см. в разделе Требования и рекомендации по обработке (интеллектуальный анализ данных).
Дополнительные сведения см. в разделе Требования и рекомендации по обработке (интеллектуальный анализ данных).
Просмотр структур интеллектуального анализа данных
Вы не можете использовать средства просмотра для просмотра данных в структуре интеллектуального анализа данных. Однако в SQL Server Data Tools можно использовать вкладку Mining Structure в конструкторе интеллектуального анализа данных для просмотра столбцов структуры и их определений. Дополнительные сведения см. в разделе конструктор интеллектуального анализа данных.
Если вы хотите просмотреть данные в структуре интеллектуального анализа данных, вы можете создавать запросы с помощью расширений интеллектуального анализа данных (DMX). Например, оператор SELECT * FROM возвращает все данные в структуре майнинга. Для получения этой информации структура интеллектуального анализа данных должна быть обработана, а результаты обработки должны быть закэшированы.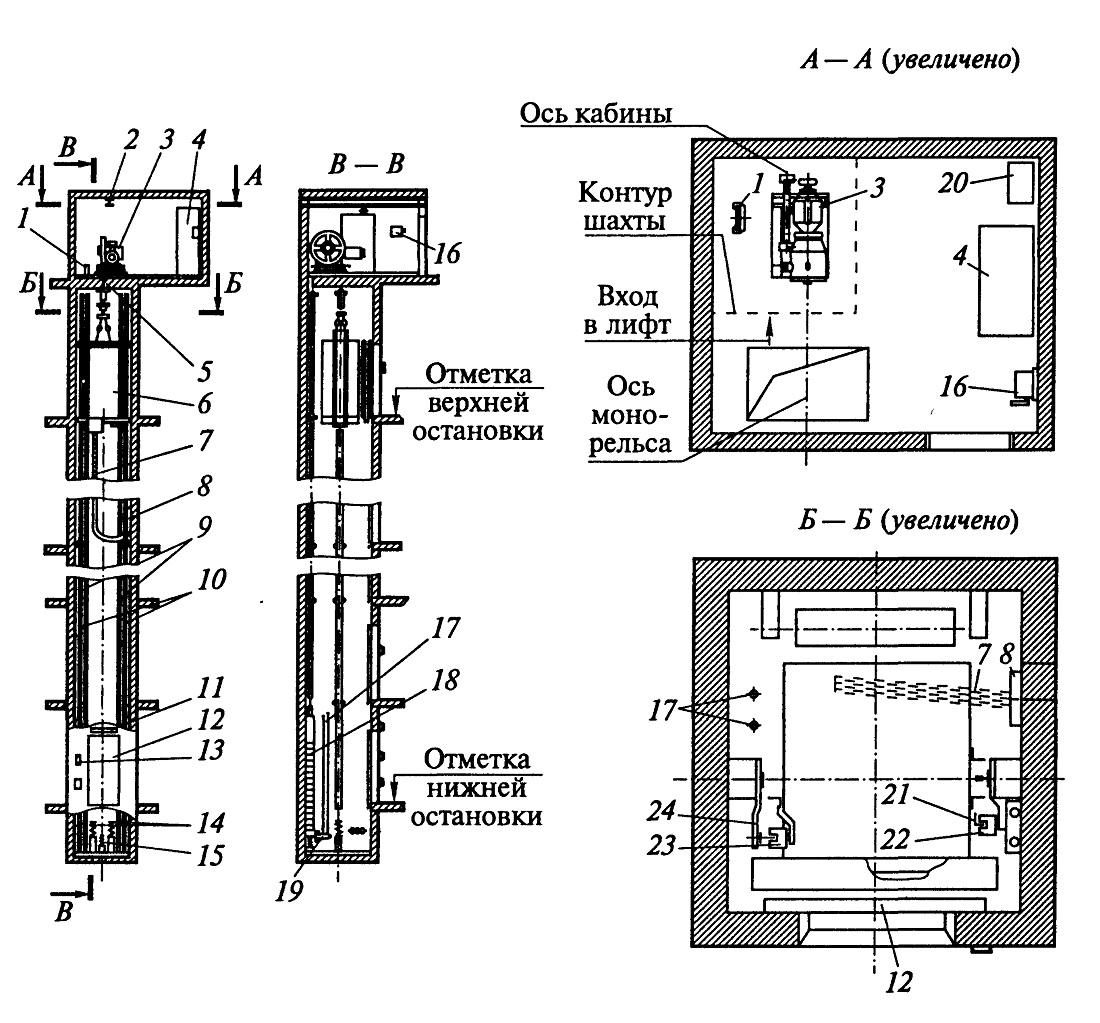
Оператор SELECT * FROM возвращает те же столбцы, но только для наблюдений в этой конкретной модели. Дополнительные сведения см. в разделах SELECT FROM
Использование моделей интеллектуального анализа данных со структурами интеллектуального анализа данных
Модель интеллектуального анализа данных применяет алгоритм модели интеллектуального анализа данных к данным, представленным структурой интеллектуального анализа данных. Модель интеллектуального анализа данных — это объект, принадлежащий определенной структуре интеллектуального анализа данных, и модель наследует все значения свойств, определенных структурой интеллектуального анализа данных. Модель может использовать все столбцы, содержащиеся в структуре интеллектуального анализа данных, или их подмножество. Вы можете добавить в структуру несколько копий столбца структуры. Вы также можете добавить несколько копий столбца структуры в модель, а затем назначить разные имена или псевдонимов для каждого столбца структуры в модели. Дополнительные сведения о псевдонимах столбцов структуры см. в разделах Создание псевдонима для столбца модели и Свойства модели интеллектуального анализа данных.
Дополнительные сведения о псевдонимах столбцов структуры см. в разделах Создание псевдонима для столбца модели и Свойства модели интеллектуального анализа данных.
Дополнительные сведения об архитектуре моделей интеллектуального анализа данных см. в разделе Модели интеллектуального анализа данных (службы Analysis Services — интеллектуальный анализ данных).
Используйте предоставленные ей ссылки, чтобы узнать больше о том, как определять, управлять и использовать структуры интеллектуального анализа данных.
| Задачи | Ссылки |
|---|---|
| Работа со структурами реляционного майнинга | Создание новой реляционной структуры интеллектуального анализа данных Добавление вложенной таблицы в структуру интеллектуального анализа данных |
| Работа со структурами майнинга на базе OLAP-кубов | Создание новой структуры интеллектуального анализа данных OLAP |
| Работа с колоннами в шахтном сооружении | Добавление столбцов в структуру интеллектуального анализа данных Удаление столбцов из структуры интеллектуального анализа данных |
| Изменение или запрос свойств и данных структуры интеллектуального анализа данных | Изменение свойств структуры интеллектуального анализа данных |
| Работа с базовыми источниками данных и обновление исходных данных | Редактирование представления источника данных, используемого для структуры интеллектуального анализа данных Обработка структуры интеллектуального анализа данных |
См.
 также
также
Объекты базы данных (службы Analysis Services — многомерные данные)
Модели интеллектуального анализа данных (службы Analysis Services — интеллектуальный анализ данных)
Шахта Quartz Hill | Продукция
Шахта HO Quartz Hill Mine
по модели Джо Креа
Комплект #221
99,99 $
Комплект #321
144,99 $
(обязательно прокрутите до конца!)
9001 Quartz Hill Mine 2 N в масштабе
дополнительная металлическая версия (выше ) — также можно построить без металлического сайдинга. Оба варианта сборки включены в комплект!
Детали включают: внутренние протравленные доски пола, внутреннюю структуру, цельную съемную крышу, дощатый сайдинг с гравировкой на наружных поверхностях стен, цельную раму с движущимися частями, части фундамента, двери котельной, окна и двери, которые можно позиционировать. открытые или закрытые, включая остекление с лазерной резкой, а также пристроенную котельную и кузницу!
Наша торговая марка ЛЕГКО следовать ПОЛНОСТЬЮ Иллюстрированные пошаговые инструкции упрощают сборку!
Прецизионная деревянная конструкция с лазерной резкой.
Включает наш бумажный гофрированный кровельный материал и кровельный материал из толя.
. ”
O = 9,6 x 12,4 дюйма
На основе измерений Кейт Пашина и Джо Креа .
Несколько вариантов конструкции, деревянный или металлический сайдинг и т. д.
См. раздел «Дизайн» ниже для некоторых включенных опций.
Особенности:
Комплект #821
219,99 $
Комплект #121
$79,99
Рудник Кварц-Хилл был одним из немногих оставшихся золотых рудников в Центральном городе — районе Блэк-Хок округа Гилпин, штат Колорадо. Исторический регион имеет богатую историю добычи золота и железных дорог. Добыча золота началась здесь в 1860-х годах, и округ Гилпин был одним из самых ранних и продуктивных районов штата. Позже, когда горнодобывающая промышленность расширилась, этот район обслуживали железные дороги Колорадо-Сентрал (позже Колорадо и Южный) и Гилпин-Трамвей.
В центре шахтерского района находился Кварц-Хилл, где эта шахта располагалась высоко на склоне горы. Это шахтное здание типично для шахт, построенных около 100 лет назад: металлический сайдинг на деревянных каркасных стенах, остроконечная крыша и закрытая конструкция шахты.
Это шахтное здание типично для шахт, построенных около 100 лет назад: металлический сайдинг на деревянных каркасных стенах, остроконечная крыша и закрытая конструкция шахты.
Холодная, зимняя горная местность требовала, чтобы шахта была полностью закрыта. Эта компактная конструкция включает в себя конструкцию подъемника и шахты, а также пристроенную котельную и кузницу (для заточки сверл). Несмотря на небольшой размер, эта шахта имела продуктивную историю, так как вокруг ее остатков находится большая свалка отходов. Зимой 2004-2005 года возраст, выветривание и изнашивание сделали свое дело, и этого сооружения больше нет.
Создатели моделей в масштабе Дикого Запада воспроизвели эту шахту, измеренную Джо Креа и исследованную Джо Креа и Китом Пашиной.
Дополнительную информацию об этой шахте можно найти в мартовско-апрельском выпуске журнала Narrow Gauge and Short Line Gazette.
Чтобы увидеть реальные фотографии этой структуры, посетите нашу страницу галереи Quartz Hill Mine
История: (Кит Пашина)
Вид спереди: Шахта Quartz Hill в масштабе N
Дизайн:
Мы включили множество вариантов для этого набора.